
IX. 深層強化学習をROS/AnyLogicに導入(2)
3.3 AnyLogicにRL4Jを実装
AnyLogicにはカスタム実験(Custom Experiment)という機能があって、そこにRL4Jを埋込めることは「信号機」のPDFに書かれていました。但し、カスタム実験はAnyLogicの無償版では使うことができず、Professional版が必要です。今の駄待ち狐にはProfessional版を使う術はないので、これから書くことは2021年にやったことの説明です。最終的にはAnyLogicのモデリングシミュレーションをRL4Jと連携させたい訳ですが、取敢えずはJavaに移植した練習問題をカスタム実験として実行することを試みました。前述のuberjarだけでなくカスタム実験の記述には独特の作法があって、なかなか一筋縄では行きません。
色々と試行錯誤して分った結論は以下の通りです。カスタム実験のPropertiesのCode:にはメインクラスのmainメソッドの{...}内のみを記載します。クラスのまま記載したり、メソッドの書式で記載するとエラーになります。Advanced JavaのAdditional class code:にメインクラス以外のクラスを記載しますが、ここではクラスの宣言から書きます。一方、各.javaファイルの冒頭にあるインポート文は、全て集約してAdvanced JavaのImports section:に記載します。ここでインポートする依存ライブラリはuberjarにする必要があります。
コマンドプロンプトでMavenプロジェクトのフォルダにcdして
> mvn assembly:assembly -DdescriptorId=jar-with-dependencies
と入力すると、targetサブフォルダの中に*-jar-with-dependencies.jarとしてuberjarが生成されます。これをDependenciesのJar files and class folders required to build the model:で読込めば、練習問題をAnyLogic上で実行できます。実際には上述したこと以外にもエラーに対処したのですが、その最終版はAnyLogicのモデルファイルの中にあって見ることができません。何にしても、練習問題がAnyLogic上で動作することは確認できました。
さて、いよいよエレベータによるフロア間移送にRL4Jを適用します。何を学習させたのかというと、搬送効率を最大化するためのエレベータの出発タイミングです。AnyLogic上の練習問題は見ることができないので再掲もできませんが、この学習プログラムは別途テキストファイルとして保存してあります。いずれAnyLogicでは見られなくなると考えた上での自衛策です。カスタム実験のAdvanced JavaのImports section:に記載したインポート文は以下の通りです。uberjarとしては練習問題用に作成したものがそのまま使えます。
コードの表示にはPrism.jsを使用しています。prism.cssの設定は団塊爺ちゃんの備忘録を参考にしました。
import org.deeplearning4j.rl4j.learning.sync.qlearning.QLearning;
import org.deeplearning4j.rl4j.learning.sync.qlearning.discrete.QLearningDiscreteDense;
import org.deeplearning4j.rl4j.network.dqn.DQNFactoryStdDense;
import org.deeplearning4j.rl4j.policy.DQNPolicy;
import org.deeplearning4j.rl4j.space.ObservationSpace;
import org.deeplearning4j.rl4j.space.ArrayObservationSpace;
import org.deeplearning4j.rl4j.space.DiscreteSpace;
import org.deeplearning4j.rl4j.space.Encodable;
import org.deeplearning4j.rl4j.mdp.MDP;
import org.deeplearning4j.gym.StepReply;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.learning.config.RmsProp;
import com.github.sh0nk.matplotlib4j.Plot;
import com.github.sh0nk.matplotlib4j.PythonConfig;
import com.github.sh0nk.matplotlib4j.PythonExecutionException;
import java.io.IOException;
import java.util.Random;
import java.util.logging.Logger;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
次にPropertiesのCode:に記載した内容は以下のようになっています。MoveToOrigin.javaのmainメソッドと基本的には同じですが、冒頭のDataManagerのインスタンスmanagerの生成はエラーが出るのでなくしました。このmanagerは27行目のdql生成時の引数になっていたのですが、これを削除しても問題なく動作します。5行目に出てくるElvatMDPは、Additional class code:に記載された環境設定クラスで、そこでstatic finalとして宣言されているMAX_STEPを引用しています。33行目の最後のpolicyの保存と、43行目の保存したpolicyのロードはEclipseでは単文ですが、AnyLogicではtry...catch構文にしないとエラーが出ます。
// Q学習のハイパーパラメータを定義
QLearning.QLConfiguration MOVE_QL = QLearning.QLConfiguration.builder()
.seed(1) // Random seed
.maxEpochStep(100) // Max step By epoch
.maxStep(ElvatMDP.MAX_STEP) // Max step
.expRepMaxSize(ElvatMDP.MAX_STEP) // Max size of experience replay
.batchSize(128) // size of batches
.targetDqnUpdateFreq(500) // target update (hard)
.updateStart(100) // num step noop warmup
.rewardFactor(1) // reward scaling
.gamma(0.99) // gamma
.errorClamp(1.0) // td-error clipping
.minEpsilon(0.1f) // min epsilon
.epsilonNbStep(1000) // num step for eps greedy anneal
.doubleDQN(true) // double DQN
.build();
// ネットワークの構成を定義
DQNFactoryStdDense.Configuration MOVE_NET = DQNFactoryStdDense.Configuration.builder()
.l2(0)
.updater(new RmsProp(0.001))
.numHiddenNodes(16) // 隠れ層のノード数
.numLayer(3) // 隠れ層の層数
.build();
// 訓練用にMoveMDPクラスのインスタンスmdp1を生成
MDP<Encodable, Integer, DiscreteSpace> mdp1 = new ElvatMDP(false);
// mdp1と訓練用パラメータで訓練を定義
QLearningDiscreteDense<Encodable> dql = new QLearningDiscreteDense(
mdp1, MOVE_NET, MOVE_QL);
// 訓練を実行
dql.train();
// 最後のpolicyを保存
try {
dql.getPolicy().save("policy.zip");
} catch (IOException e) {
e.printStackTrace();
}
mdp1.close();
// テスト用にMoveMDPクラスのインスタンスmdp2を生成
MDP<Encodable, Integer, DiscreteSpace> mdp2 = new ElvatMDP(true);
// 保存したpolicyをロード
DQNPolicy<Encodable> pol = null;
try {
pol = DQNPolicy.load("policy.zip");
} catch (IOException e) {
e.printStackTrace();
}
// ロードしたpolicyでテストを実行(エピソードでは区切らず1,000往復する)
System.out.println("Test is starting.....");
pol.play(mdp2);
mdp2.close();
3.4 AnyLogicモデルとRL4Jの連携
Additional class code:に記載したElvatMDPクラスは以下の通りです。練習問題のMoveMDP.javaに相当するもので大枠の書式は同じですが、やっている中身は全く違います。ここでAnyLogicのモデルと連携する訳ですが、ElvatMDPの方が主体となってモデルの動作を制御します。81~107行目のreset()メソッドで生成するengineインスタンスがシミュレーションを実行し、rootはモデルのMainクラスのインスタンスです。engineとrootの宣言は17行目と19行目で行われています。96行目のengine.start(root);でシミュレーションを開始します。
// MDPインターフェースの全てのメソッドを実装したMoveMDPクラスを定義
public class ElvatMDP implements MDP<Encodable, Integer, DiscreteSpace>
{
// プログラム全体に共通の定数をstatic finalとして宣言
static final boolean RWD_FLG = true; // per trip: true, per time: false
static final int MAX_STEP = 50000; // 訓練時の最大ステップ数
static final int MAX_TRAIN_TRIP = 10; // 訓練時のエピソード当たりの往復回数
static final int MAX_TEST_TRIP = 1000; // テスト時の往復回数(1エピソードとして実行)
// 以下はインスタンス変数
boolean modeFlg; // train: false, test: true
boolean done; // episode終了フラッグ
int stepCnt= 0; // ステップ数のカウンタ(reset()でリセットしない)
int tripCnt; // 往復した回数のカウンタ(reset()でリセットする)
int tripMax; // episode当りの往復回数
double startWait; // エレベータの1Fでの待機開始時刻(trip開始時刻)
// Engineクラスのインスタンスengineを宣言するが、生成するのはreset()の中
Engine engine;
// Mainクラスのインスタンスrootを宣言するが、生成するのはreset()の中
Main root;
// Plotクラスのインスタンスpltを宣言するが、OSによってcreateの引数が異なるため生成するのはコンストラクタの中
Plot plt;
// エレベータの待機時間と1回に運搬したカゴ車の台数をプロットするためのリストを宣言
List<Double> aryWait = new ArrayList<Double>();
List<Double> aryRbps = new ArrayList<Double>();
// コンストラクタでインスタンス生成時の引数を受取る
ElvatMDP(boolean modeFlg){
this.modeFlg = modeFlg;
if(modeFlg) {
tripMax = this.MAX_TEST_TRIP;
} else {
tripMax = this.MAX_TRAIN_TRIP;
}
// OSがWindowsかどうかを判別して、python実行ファイルのpathを指定する
boolean isWindows = System.getProperty("os.name").toLowerCase().startsWith("windows");
String pyPath;
if(isWindows) {
pyPath = "C:\\Users\\kenichi\\anaconda3\\python.exe";
} else {
pyPath = "/home/kenichi/anaconda3/bin/python3.8";
}
plt = Plot.create(PythonConfig.pythonBinPathConfig(pyPath));
}
/* 観測空間と行動空間のサイズを規定: ArrayObservationSpaceではINDArray(deeplearning4jにあるNumPyの代用)
* が使われており、"Nd4j.create(new int[]{2})"で要素"0"が2個の1次元INDArrayが生成される。ここで指定されて
* いるintは{}の中の数値がintという意味で、配列要素がintという意味ではない(Javaではdoubleのゼロも"0"と表記) */
ObservationSpace<Encodable> observationSpace = new ArrayObservationSpace<>(new int[]{2});
DiscreteSpace actionSpace = new DiscreteSpace(2);
public ObservationSpace<Encodable> getObservationSpace() {
return observationSpace;
}
public DiscreteSpace getActionSpace() {
return actionSpace;
}
public Encodable getObservation() {
return new Encodable() {
// hallFloor1と2のsize(RBPの台数)をMainのgetState関数で取得し、配列に変換して返す
public double[] toArray() {
double[] state = root.getState();
return state;
}
// 上記の配列をINDArrayに変換して返す
public INDArray getData() {
double[] state = this.toArray();
INDArray stateIND = Nd4j.create(state);
return stateIND;
}
// isSkipped()がtrueだとactionが更新されない?
public boolean isSkipped() {
return false;
}
// よく分からないが、実装しないとエラーになる
public Encodable dup() {
return null;
}
};
}
public Encodable reset() {
if(engine != null) {
engine.stop();
}
// Create Engine, initialize random number generator:
engine = createEngine();
// seedの値が同じだと、シミュレーションを繰返しても同じ乱数系列が使用される
engine.getDefaultRandomGenerator().setSeed(System.currentTimeMillis());
// Selection mode for simultaneous events:
engine.setSimultaneousEventsSelectionMode(Engine.EVENT_SELECTION_LIFO);
// Create new root object:
root = new Main(engine, null, null);
// Setup parameters of root object here
root.setParametersToDefaultValues();
// Prepare Engine for simulation:
engine.start(root);
// episode終了フラッグ、tripカウンタのリセット
done = false;
tripCnt = 0;
// delayClose1が待ち状態となるまでシミュレーションを早送りする
while(root.delayClose1.size() == 0) {
engine.runFast(root.time() + 1.);
}
// エレベータの待機時間を算出するため、その開始時刻を記録
startWait = root.time();
return getObservation();
}
public void close() {
}
// 各stepごとに呼ばれるメソッド
// actionを受け取り、次のstateとreward、episodeが終了したかどうかを返す
public StepReply<Encodable> step(Integer action) {
double reward = 0.; // reward
long numRbps = 0; // カゴ車の台数
double[] state = root.getState(); // 1F/2Fのカゴ車待機台数を配列で取得
stepCnt++;
// delayClose1が待ち状態となるまでの1回目の早送りはreset()の中で実行済み
// 取得したaction(0 or 1)が1の時に、delayClose1の待ち状態が解消されるまで早送りする
if((int)action == 1) {
// 待機時間を計算し、後でプロットするためにリストで保存(訓練時は各エピソードの最終tripのみ)
double waitTime = root.time() - startWait;
if(modeFlg || tripCnt == 9) {
aryWait.add(waitTime / 20.);
}
// 実際は1回の.stopDelayForAll()で待ち状態は解消されるが、念のため繰返す
while(root.delayClose1.size() == 1) {
root.delayClose1.stopDelayForAll();
engine.runFast(root.time() + 1.);
}
// delayClose1が待ち状態となるまでシミュレーションを早送りする
while(root.delayClose1.size() == 0) {
engine.runFast(root.time() + 1.);
// hallFloor1か2のsize()が8以上になったらepisodeを終了し、ペナルティとして負の報酬
if((state[0] >= 8.) || (state[1] >= 8.)) {
done = true;
reward = -1.;
break;
}
}
// 各tripの所要時間を算出し、待機開始時刻を現在時刻にリセットする
double tripTime = root.time() - startWait;
startWait = root.time();
// 5秒早送りしないと前回運んだ台数のままになっている
engine.runFast(root.time() + 5.);
numRbps = root.closeElevator1.size();
// 1回当りと、時間当りで異なる正の報酬を与える
if(RWD_FLG) {
reward = numRbps / (tripMax * 5.);
} else {
reward = numRbps / (tripMax * tripTime / 30.);
}
// 後でプロットするために、一往復で運んだ台数をリストで保存(訓練時は各エピソードの最終tripのみ)
if(modeFlg || tripCnt == 9) {
aryRbps.add((double)numRbps);
}
tripCnt++;
// episode当りの最大往復回数になったらepisodeを終了する
if(tripCnt >= tripMax) {
done = true;
}
// testモードの時は一往復の時間、待機時間、運搬台数を出力する
if(modeFlg) {
System.out.println("trip: " + tripCnt);
System.out.println(" time: " + tripTime);
System.out.println(" wait: " + waitTime);
System.out.println(" RBPs: " + numRbps);
// 最後の往復でトータルの所要時間と運搬台数を表示する
if(tripCnt == MAX_TEST_TRIP) {
System.out.println("total");
System.out.println(" time: " + root.time());
double sumRbps = 0.;
for (int i = 0; i < aryRbps.size(); i++) {
sumRbps += aryRbps.get(i);
}
System.out.println(" RBPs: " + (int)sumRbps);
}
}
// actionが0の時は、10秒早送りし、1回当り最大化の場合は0.01のrewardを付与
} else {
engine.runFast(root.time() + 10.);
if(RWD_FLG) {
reward = 0.01;
}
// hallFloor1か2のsize()が8以上になったらepisodeを終了し、ペナルティとして負の報酬
if((state[0] >= 8.) || (state[1] >= 8.)) {
done = true;
reward = -1.;
}
}
// 最後の往復(モードによって判定方法は異なる)で待機時間と運搬台数をプロットする
String title;
String xlabel;
if(modeFlg) {
title = "1,000 Test Trips";
xlabel = "TRIPS (ALL RUNS)";
} else {
title = "50,000 Train Steps";
xlabel = "TRIPS (ONE IN TEN TIMES)";
}
if(modeFlg && (tripCnt == MAX_TEST_TRIP) || !modeFlg && (stepCnt == MAX_STEP)) {
plt.plot().add(aryRbps).color("blue").linewidth(0.5).label("Carried RBPs");
plt.plot().add(aryWait).color("red").linewidth(0.3).label("Waiting Time");
plt.xlim(0, aryRbps.size());
plt.ylim(0., 9.);
plt.legend().loc("upper right");
plt.title(title);
plt.xlabel(xlabel);
plt.ylabel("TIME (x 20 sec) / NUMBER OF RBPs");
try {
plt.show();
} catch (IOException|PythonExecutionException e) {
System.out.println(e);
}
}
return new StepReply(getObservation(), reward, isDone(), null);
}
public boolean isDone() {
return done;
}
// DQNでは必要ないが、実装しないとエラーになる
public MDP<Encodable, Integer, DiscreteSpace> newInstance(){
return null;
}
}
さて、ここからが悩みどころでした。エレベータによるフロア間移送で、DRLのaction、state、rewardを何にするのか、そもそもステップとエピソードをどう区切るのか、最初は全く雲を掴むような話でした。本稿をお読みの方にはそもそものモデル自体も分らないと思いますので、まずこれを紹介します。無償版でも動作するようにカスタム実験を除いたモデルを作ってあるので、これをZIPでダウンロードして下さい。解凍したフォルダ内にあるElevator_9.alpをAnyLogicで開くと、モデルを動作させることができます。これが駄待ち狐が最初に作ったモデルで、作業員がエレベータを使ってかご台車を運んでいます。
「VIII. AMRのモデリングシミュレーション」ではElevator以外のAgentはAmrCartでしたが、このモデルではWorkerではなくRbp(かご台車)がAgentです。Tutorialsの"Job Shop"でもPalletがAgentで、ForkliftTruckはAgentが使うResourceという建付けです。「かご台車の方が作業員を使うの?!」と思いましたが、この時はTutorialsの言う通りにしました。Mainロジックの2nd Floorと1st FloorはRbpの動きなのでConnectorで繋がっています。ElevatorのフローにあるopenFloor1ブロック(エレベータが1階で扉を開けて停止中)は、1st FloorのunloadFromElevatorブロック(エレベータからの荷出し)が終ると待機解除となります。
この後のdelayClose1ブロック(エレベータの扉を閉める)は10秒間という固定値ですが、DRLではこの待機時間、つまり2階に向けて出発するタイミングを学習することにしました。これをどのようにElvatMDPクラスに実装したかというと、モデルのdelayClose1の待機状態はMainロジックの中では解除されないようにします。そして、114~218行目のstep()メソッドの中でaction == 1であれば129行目で待機を解除し、130行目で次に待機状態になるまでシミュレーションを早送りします。一方、action == 0であれば182行目でシミュレーションを10秒早送りします。この時はdelayClose1を解除しないので、10秒間出発待機となる訳です。
action == 0であれば10秒間の待機が1ステップ、action == 1であれば次に待機状態になるまでが1ステップというアンバランスな構成ですが、これでよしとしました。エピソードについては、160~161行目でtripMax回だけElevatorが往復したら終了としており、tripMaxは訓練時は10回、テスト時は1,000回(エピソードは区切らない)としました。stateは61行目あるいは117行目でstate = root.getState();としていますが、getState()関数はモデルのMainロジック内で定義されており、1階と2階のエレベータホールに溜ったかご台車の台数を要素とする配列を返します。
最後にrewardですが、2通りの報酬を考えて5行目で宣言するRWD_FLGの真偽でどちらかを設定するようにしました。trueであればエレベータに積む台数が多いほどよい、falseであれば時間当りに運べる台数が多いほどよいとして、149~153行目でそれぞれのrewardを与えています。後者の学習結果は単純で、余計な待機時間はゼロがベストです。前者は待機するほどエレベータに積む台数は増えますが、ホールに溜ったかご台車がオーバーフローするとepisodeを終了して負の報酬を与えるという制約が135~140行目にあります。この場合は制約の範囲内で待てるだけ待つことになり、訓練経過とテスト結果のグラフは以下のようになりました。
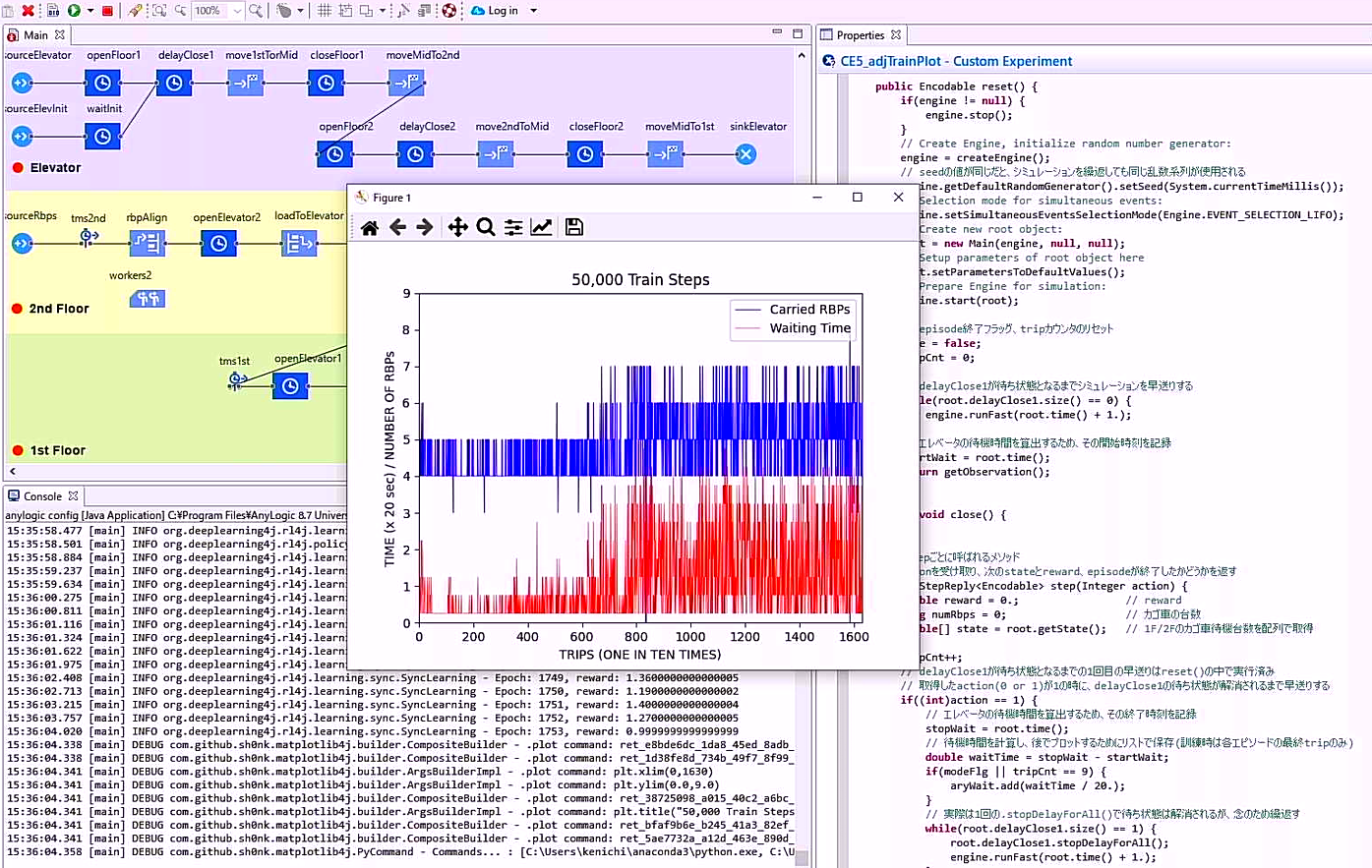 画像を新しいタブで開くと高解像度で見ることができます。
画像を新しいタブで開くと高解像度で見ることができます。
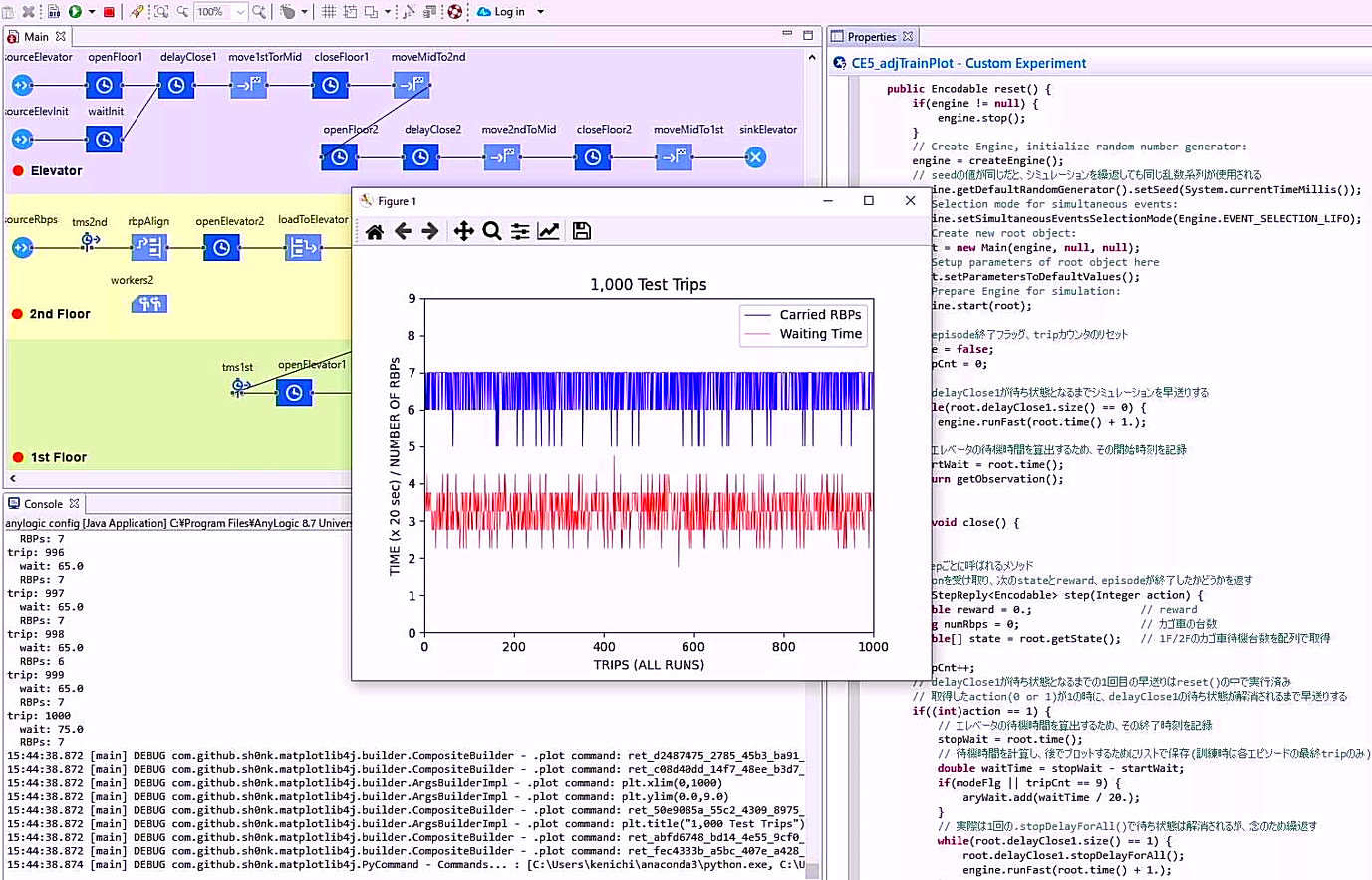 画像を新しいタブで開くと高解像度で見ることができます。
画像を新しいタブで開くと高解像度で見ることができます。
4. DRLでAMRの進路を決定(ROS1)
デタラメしか言わないROS1の画像DL、当り前のことしか言わないAnyLogicのDRLを経て、ROS1のDRLに挑戦です。本節で紹介するプログラムは全てTARで丸ごとダウンロードできます。このTARファイルは「VII. ROSによるAMRのシミュレーション」の「4. ROS1パッケージの修正」で引用したものと同じで、解凍したsrcフォルダをcatkin_wsに入れてcatkin_makeすれば動作します。但し、Ubuntu 20.04でNoeticをインストールしてあるか、22.04で「JammyでもNoeticしたい」をしてあるのが動作の前提となります。
ROS1のDRLでまず参考にしたのは、解凍したsrc/turtlebot3_machine_learningフォルダ内にあるturtlebot3_dqnです。このパッケージについては"Machine Learning - TurtleBot3"に解説がありますが、ROS2 DashingとROS1 Melodicにしか対応していません。MelodicはNoeticの一つ前のバージョンです。色々と出てくるエラーに対処して何とかNoeticで動くようになったのですが、レッツノートで動作させると6時間かけて15エピソード目まで進んだところでターミナル上の計算が止り、マウスの応答が異様に遅くなってディスクへの書込みランプが点灯し続けるという異常事態に陥ったため、電源スイッチで強制的にシャットダウンしました。
これではどうしようもないので、まずこのturtlebot3_dqnをちゃんと動作するようにしました。修正したプログラムと動作の詳細は4.1項で述べますが、ゴールは正方形のエリア内に入ればよいという緩いもので、TB3が障害物に衝突すると原点に戻って最初からやり直すことになっています。駄待ち狐としてはナビの代替をDRLでやらせたかったのですが、このアプローチでは目標姿勢(位置と向き)に合致するのがゴールというのは不可能に思えました。ただ、なるべく衝突しないようにした上で、やり直しはせずに継続して走行するようにしました。最終的なプログラムdqn_drive3の動作は以下のキャプチャ動画のようになっています。
DRLの学習は3つのステージで順番に行います。いきなり遠方のゴールを指定すると、いつまで経っても学習できないからです。動画開始6秒後にGazebo上に現れる赤い正方形がステージ1のゴールです。tb3_0は円柱に囲まれた左下のエリアをウロウロした後、46秒後にようやく正方形内に入ります。するとこの正方形は消えて、出発地点に赤い正方形が出現します。これで帰路につく訳です。49秒後に画面がスキップしますが、左上のグラフに表示される通りスキップ後は27行程を終了した後になります。tb3_0の位置はRVizで確認して下さい。53秒後に出発地点に戻った後、1分13秒後にすんなりとゴールします。これが学習の効果です。
1分17秒後に画面がスキップしますが、次はステージ2になります。1分24秒後に現れるゴールは少し遠くなっています。tb3_0はステージ1のゴール位置で少し戸惑いますが、1分41秒後にはゴールします。1分46秒後にスキップした後は17行程走行後で、2分14秒後にゴールします。2分18秒後からはいよいよステージ3です。2分23秒後に出現するゴールはナビの目標姿勢に対応する位置にあります。これはなかなかゴールできないので2分43秒後にスキップが入りますが、3分0秒後にゴールします。この時の所要時間はグラフ上欄にある通り231秒です。スキップした後は5行程走行後で、3分11秒から3分51秒までスキップなしの40秒で帰路完走です。
4.1 turtlebot3_dqnの修正
turtlebot3_dqnの元のプログラムはsrc/turtlebot3_machine_learning/turtlebot3_dqn/srcフォルダに入っています。ステージ1から4の個別のプログラムがあって、課題がだんだん難しくなって行きます。turtlebot3_dqn_stage_1~4が「3.1 Python(Keras-RL)の練習問題」に出てくるmain.pyに相当し、moveEnv.pyに当るのはturtlebot3_dqn/environment_stage_1~4.pyです。これを見ると、kerasは使っていますがkeras-rlとgymは使っていません。そこで練習問題で動作が確認できているkeras-rlとgymを使ってプログラムを書換えました。それがtb3_dqn_1~4とdqnEnv_1~4.pyになります。
ステップとエピソードの区切りや、action、state、rewardについては元のプログラムを踏襲しています。tb3_dqn_1~4をローンチするのはsrc/turtlebot3_machine_learning/turtlebot3_dqnフォルダ以下にあるlaunch/dqn_gym.launchで、ステージはパラメータで指定します。ステージ1と2は、以下の各コマンドで動作させることができます。
$ roslaunch turtlebot3_dqn dqn_gym.launch stage:=1 mode:="first" steps:=2000 $ roslaunch turtlebot3_dqn dqn_gym.launch stage:=2 mode:="first" steps:=5000
modeは既に学習済みのweightsを利用するかどうかで、firstなら利用しません。stepsはプログラムを終了する総ステップ数です。
プログラムを開始すると、TB3のBurgerが原点から出発して赤い正方形で示されたゴールを目指します。①ゴールする、②壁か円柱に衝突する、③指定した最大ステップ数(300に設定)に達するの何れかでエピソードは終了し、①の場合はゴール位置が更新されます。最初はグルグル回ったり、ウロウロしたりしている内に衝突してしまいますが、エピソードを重ねるごとに学習してゴールに直行するようになります。表示されるグラフはエピソード毎の平均報酬で、プログラム終了時に上記turtlebot3_dqnフォルダ以下にplots/plot.pngとして保存されます。weightsは同じ場所にweightsフォルダとして保存されます。
ステージ3と4は以下のコマンドで実行できますが、この場合はmodeがfirstだとなかなか学習しません。contにしてステージ2で学習したweightsを使うと、スムーズに学習が進みます。
$ roslaunch turtlebot3_dqn dqn_gym.launch stage:=3 mode:="cont" steps:=5000 $ roslaunch turtlebot3_dqn dqn_gym.launch stage:=4 mode:="cont" steps:=5000
ただ、どのステージにおいても学習がうまく進むかどうかは偶然に左右されます。全く学習が進まなくても「このプログラムおかしいんじゃない!」と思わないで下さい。ステージ2でうまく学習できたweightsがweights_log/2_weights_stage2_firstとして保存されているので、ステージ3と4はこれを使ってcontにするとうまく学習します。
4.2 dqn_drive3の全体構成
キャプチャ動画をお見せしたdqn_drive3の各ステージは
$ roslaunch mtb3_sim dqn_drive3.launch stage:=1 ver:=18 mode:="first" $ roslaunch mtb3_sim dqn_drive3.launch stage:=2 ver:=18 mode:="cont" $ roslaunch mtb3_sim dqn_drive3.launch stage:=3 ver:=18 mode:="cont"
によってローンチされます。ローンチファイルはsrc/mtb3_sim/launch/dqn_drive3.launchです。前項のdqn_gym.launchからこのdqn_drive3.launchに至るまでには多くの試行錯誤と紆余曲折がありますが、それを時系列で紹介しても分りにくいだけなので最後のバージョンを基に説明します。dqn_drive3.launchの関連ファイルは下図の依存関係にあります。DQNノードはtb3_0の進路をDRLで決めるもので、ドライブノードはそれ以外の4台のTB3を走行させます。
dqn_drive3.launch ⇒ tb3_drive_18 ⇒ base_drive_18.py (baseDriveクラス)
│ ドライブノード生成 インスタンス生成 ↑
│ │ 継承
└⇒ mtb3_dqn_18 ⇒ dqnEnv_18.py ⇒ act_drive_18.py (actDriveクラス)
DQNノード生成 インスタンス生成 インスタンス生成
ローンチファイル以外の5つのファイルは全てsrc/mtb3_sim/srcにあります。tb3_drive_18とbase_drive_18.pyについては「VII. ROSによるAMRのシミュレーション」の「4.4 ドライブノード」で説明済みです。mtb3_dqn_18はDQNのネットワーク定義をして訓練とテストを実行するkeras-rlの常套コードですが、19行目でmtb3_dqnをROSのノードとして起動し、20~22行目ではローンチファイル実行時に指定したパラメータを受取っています。バージョン番号が18なのはdqnEnv_18.py、act_drive_18.pyと番号を揃えているだけで、何回も修正を重ねたということではありません。
dqnEnv_18.pyにあるEnvクラスは、tb3_0の進路を決定するactDriveクラスと連携して動作します。DRLのステップとaction、stateは次項で説明するactDriveで規定しているので、ここではエピソードとrewardについて説明します。turtlebot3_dqnでは①ゴールする、②衝突する、③指定したステップ数に達するの何れかでエピソードを終了していましたが、dqnEnv_18.pyでは111~117行目にある通り①と③だけにしています。ドライブノードのbaseDriveを継承するactDriveによって衝突しないように走行するので、②は必要ないとしたのです。さらに、198~223行目で①の時だけゴール位置を更新(往路と復路を切替え)するようにしました。
120~144行目のsetReward()関数では、ゴールしたらreward = 200.とし、250ステップでゴールできなかったらreward = -150.にしています。それ以外のステップのrewardはyaw_reward[]とdistance_rateから算出されます。この難解な計算式はturtlebot3_dqnの元のプログラムで使われていたものを踏襲しているのですが、yaw_reward[]の要素trの計算式は元の
angle = -pi / 4 + heading + (pi / 8 * i) + pi / 2 tr = 1 - 4 * math.fabs(0.5 - math.modf(0.25 + 0.5 * angle % (2 * pi) / pi)[0])
という煩雑な式をこれと等価で簡単な
tr = 1. - 2 * math.fabs((heading / pi + (i - 2) / 8 + 1) % 2 - 1)
に置換えました。両式が等価であることは、iを0~4とした時のheadingとtrの関係が何れも下記のグラフになることで確認できます。
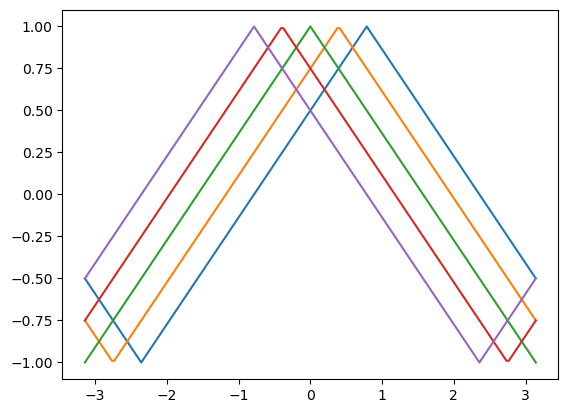
headingというのはtb3_0の現在の向きと、現在位置からゴールを見た方向の差分なので、両者がずれるに従ってtrは小さくなります。5本の線の内どれを使うかはactionによって変り、actionはtb3_0の角速度を決めているので、差分が小さくなる方向の角速度であればyaw_reward[action]は大きくなります。一方、distance_rateは現在位置からゴールまでの距離current_distanceに依存しています。ですから、yaw_reward[]とdistance_rateを報酬に反映させるというのは納得がいくのですが、なぜ143行目の式なのかは皆目分りません。そこで、yaw_reward[]とdistance_rateを加算するという式も試してみたのですが、全く学習しませんでした。
4.3 actDriveクラスの役割
「VII. ROSによるAMRのシミュレーション」の「4.4 ドライブノード」に記載の通り、baseDriveクラスでは①広前方と側方の障害物までの距離が所定値以上の場合は、直進、緩旋回進行、急旋回進行の何れかを選択し、②広前方か側方の障害物までの距離が所定値未満の場合はその場旋回させます。actDriveではactionによって並進速度と角速度を決定しますが、②は衝突回避のための緊急動作なのでaction任せにはできません。①の場合のみactionによって速度を決定します。①の速度を決定するのはbaseDriveでもactDriveでもsetVel()関数です。
baseDriveのsetVel()はbase_drive_18.pyの62~78行目にあり、前方の障害物までの距離が所定値未満の場合は反対方向に急旋回、正面の障害物までの距離が所定値未満の場合は反対方向に緩旋回、障害物がなければ最大並進速度で直進となっています。actDriveはbaseDriveを継承していますが、act_drive_18.pyの38~46行目にsetVel()があってbaseDriveのsetVel()をオーバーライドしています。actDriveのsetVel()では、actionが0なら左急旋回、1なら左緩旋回、2なら直進、3なら右緩旋回、4なら右急旋回です。前項で示した依存関係のツリーで、上下に分れたノードがクラスの継承でまた繋がるというのが「美しい予定調和の依存関係」の意味です。
上記のsetVel()を呼出すpubVel()関数はactDriveの中でオーバーライドされておらず、actDriveでもbaseDriveの80~116行目にあるpubVel()関数がそのまま使われます。その中の86~88行目でself.getScan3()のスキャンデータが更新されるまで待つことになっています。getScan3()関数ではwaffle_pi3の首側のLiDARのスキャンデータを取得しており、そのスキャン周期は1Hzです。スキャンデータはスキャンが完了するごとに更新されるので、DRLのステップも1Hzで刻まれることになります。但し、緊急動作のその場旋回の場合は、actionの値は動作に反映されません。
最後にstateですが、まずdqnEnv_18.pyの98~118行目にあるgetState()関数を見て下さい。101行目にあるscan_range = self.drive.scan_rangeはactDriveのインスタンスdriveが返す24方位のスキャンデータです。その取得方法は後述します。103~105行目のheadingとcurrent_distanceはrewardの計算式の中に出てきました。106~107行目のobstacle_min_rangeとobstacle_angleはscan_rangeの中の最小値と最小値になる角度です。scan_rangeは要素数24のリストなので、これにその後の4つの値を要素として加えたリストがstateとなります。
24方位のスキャンデータを取得する方法ですが、turtlebot3_dqnではBurgerモデルを変更しています。src/turtlebot3/turtlebot3_description/urdf内にあるturtlebot3_burger.gazebo.xacroの111行目を見ていただくと<samples>24</samples>となっています。元々は24が360になっていて1°刻みのデータを出力していましたが、これで24方位のデータしか出力しないようになります。しかし、waffle_pi3のLiDARは首側は前半分、尾側は後ろ半分しかスキャンせず、1°刻みのデータ取得も変えるわけにはいきません。そこでactDriveでオーバーライドしたgetScan3()関数の中の23~24行目で全周24方位のスキャンデータを生成しています。