
IX. 深層強化学習をROS/AnyLogicに導入(3)
5. DRLで回復行動を決定(ROS2)
前節で紹介したdqn_drive3のDQNノードは、なかなか学習しなかったり、うまく学習したりと偶発性に左右されながらも、徐々に学習が進んで行くというDRLらしい挙動です。dqn_drive3はROS1ですが、これと同じ考え方でROS2のdqn_driveも作成して同様の挙動を確認しています。一方、「VII. ROSによるAMRのシミュレーション」の「5. ROS2への移植」で紹介したナビノードと比較すると、DQNノードの非力さは歴然です。ナビノードでは目標姿勢にピタッと止るのに対し、DQNノードは大きな正方形内に入ればいいという大甘のゴール認定です。これではDRLを使っている意味はなく、ナンチャッテAIだと言わざるを得ません。
DRLを使ってナビノードよりも高性能のノードを作るにはどうしたらいいかと頭を悩ませて考えついたのは、基本的にはナビノードを使って、判断を迫られる局面でDRLを使えば、ナビノードとDRLのいいとこ取りができるのではないかということです。ナビノードで判断を迫られる局面といえば回復行動です。ナビノードではnavigate_to_pose_w_replanning_and_recovery.xmlに記載された手順に従って回復行動を取りますが、どの回復行動がベストかはstateから判断できそうです。stateに基づくactionで回復行動を選択すれば、ただ順番に回復行動を試すよりもいい結果が得られると思いました。
この考えで作成したプログラムの最終バージョンはdqn_navi5で、TARでダウンロードできます。このTARファイルは「5. ROS2への移植」に登場したnavi_drive9のTARファイルとは異なります。navi_driveとdqn_naviは並行して開発していましたが、回復行動を規定するファイルが違っています。それぞれが別のファイルを参照するように構成できればよかったのですが、一旦dqn_naviを検討して次にnavi_driveを実行すると、回復行動ファイルを元に戻したつもりでもうまく動作しなくなります。そこでros2_wsフォルダを別々にせざるを得ませんでした。
TARを解凍してcolcon buildする手順は「5. ROS2への移植」の第3段落に記載した方法と同じです。dqn_navi5の動作にはkerasが必要ですが、kerasはAnacondaで実装する場合が多いと思いますので、conda環境に関する注意書きを遵守して下さい。dqn_navi5は
$ ros2 launch mtb3_sim dqn_navi5.launch.py mode:="first" steps:=100 $ ros2 launch mtb3_sim dqn_navi5.launch.py mode:="cont" steps:=100 $ ros2 launch mtb3_sim dqn_navi5.launch.py mode:="test" steps:=100
の何れかで動作させます。modeがfirstなら初めての訓練、contなら学習済みのweightsを利用した継続訓練というのはdqn_drive3と同じで、testだとテストになります。また、訓練時のstepsはプログラムを終了する総ステップ数ですが、テスト時はエピソード数(ゴール回数)です。
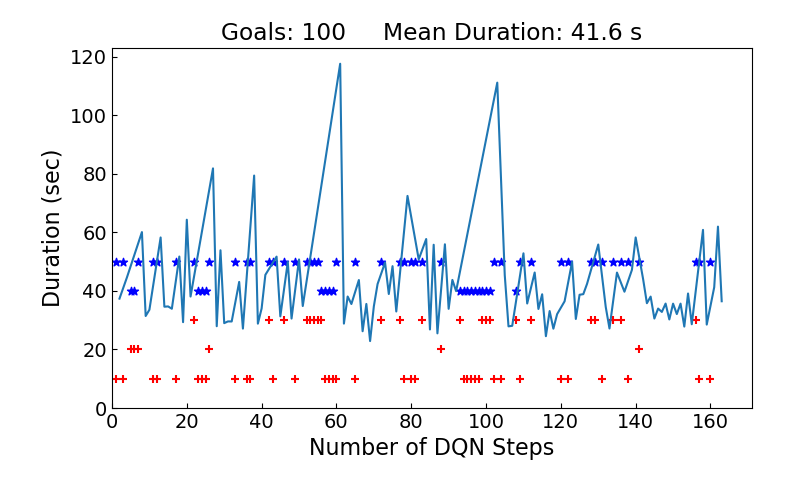
上に示すキャプチャ動画は3番目のコマンドを実行した時のもので、GazevoとRVizに表示されるtb3_0の動きはnavi_drive9のキャプチャ動画とほぼ同じです。大きく違うのは画面左上のグラフで、1分21秒後に画面がスキップした後を見ていただくと、折れ線グラフに加えて赤の"+"と青の"*"が打たれています。グラフの横軸はDQNステップで、赤+はそのステップで取った回復行動(actionと対応)を示します。actionは0~2の3種類で、この赤+の縦軸は秒数ではなく、10はactionが0、20は1、30は2という意味です。青*の方はその回復行動が有効であったかどうかを示しており、50は有効、40は効果がなかったという意味です。
一方、折れ線グラフをよく見ていただくと、値を持つ頂点(ブレークポイント)は+と*がないステップにあることが分ります。このステップではゴールしたので回復行動は取らなかった(+と*はない)代りに行程時間が折れ線で表示されるのです。横軸が等間隔にはなっていませんが、折れ線グラフはnavi_drive9のグラフと同じものになります。3分55秒後に100回目のゴールをするとプログラムが終了するので、最後の行程時間を含むグラフはキャプチャ動画には表示されませんが、ファイルに保存されるので以下に示します。行程時間が偶発性に左右されることを考えると、navi_drive9の43.3秒から改善されたとは言いづらい状況です。
5.1 dqn_navi5の全体構成
以下のファイルツリーは dqn_navi5のソースコードの依存関係を示しています。navi_drive9で示した依存関係ツリーと同様に、駄待ち狐が新たに作成・修正したファイルのみを載せています。但し、今回はnavi_drive9から変化のあったファイルに着色しています。全体のローンチファイルdqn_navi5.launch.pyは当然ながら新規作成ですが、navi_drive9.launch.pyからの変更箇所はmtb3_navi_2.pyではなくmtb3_dqn_5.pyを起動するというところだけです。mtb3_dqn_5.pyがmtb3_sim/srcフォルダではなくmtb3_py/mtb3_pyフォルダにある理由は「VII. ROSによるAMRのシミュレーション」の「5.2 ドライブノード」で説明した通りです。
[mtb3_sim/launch/] dqn_navi5.launch.py
⇒ [mtb3_sim/launch/] spawn_turtlebot3_ns8.launch.py
(w/ [mtb3_sim/models/turtlebot3_waffle_pi4/] model.sdf)
⇒ [mtb3_sim/launch/] turtlebot3_drive_ns12.launch.py
⇒ [mtb3_py/mtb3_py/] tb3_drive_5.py
⇒ [mtb3_py/mtb3_py/] base_drive_5.py
⇒ [mtb3_py/mtb3_py/] mtb3_dqn_5.py
⇒ [mtb3_py/mtb3_py/] dqnEnv_5.py
⇒ [navigation2/nav2_simple_commander/nav2_simple_commander/]
robot_navigator.py
⇒ [navigation2/nav2_bringup/launch/] bringup_launch_2.py
(w/ [turtlebot3/turtlebot3_navigation2/param/] waffle_pi4.yaml)
⇒ [navigation2/nav2_bringup/launch/] navigation_launch_2.py
⇒ [navigation2/nav2_bt_navigator/src/] bt_navigator.cpp
(w/ [navigation2/nav2_bt_navigator/behavior_trees]
navigate_to_pose_w_replanning_and_recovery.xml)
⇒ [navigation2/nav2_collision_monitor/launch/]
collision_monitor_node.launch.py
(w/ [navigation2/nav2_collision_monitor/params/]
collision_monitor_params.yaml)
⇒ [navigation2/nav2_collision_monitor/src/]
collision_monitor_node.cpp
mtb3_dqn_5.pyはdqn_drive3(ROS1)のmtb3_dqn_18と同じく、DQNのネットワーク定義をして訓練とテストを実行するkeras-rlの常套コードです。その常套コードの部分についてはROS1のmtb3_dqn_18とROS2のmtb3_dqn_5.pyで違いはないのですが、mtb3_dqn_5.pyでは72行目にテストを実行するdqn.test()を追加しました。DRLは訓練の過程で学習していくので、訓練だけを実行していても学習成果を見ることができます。ただ、本来は訓練したweightsを使って改めてテストを実行することで学習が反映された動作を確認すべきなので、mtb3_dqn_18にテストがなかったのが手落ちでした。
コードの表示にはPrism.jsを使用しています。prism.cssの設定は団塊爺ちゃんの備忘録を参考にしました。
#!/usr/bin/env python
import os
import rclpy
from rclpy.node import Node
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
from mtb3_py.dqnEnv_5 import Env
class DqnDriveNode(Node):
def __init__(self):
super().__init__('mtb3_dqn')
dsEpisMax = 300 # エピソード当りの最大dqnステップ数
state_size = 4
action_size = 3
self.declare_parameter('mode', rclpy.Parameter.Type.STRING)
self.declare_parameter('steps', rclpy.Parameter.Type.INTEGER)
mode = self.get_parameter('mode').value
# 訓練の場合はトータルのdqnステップ数、テストの場合はエピソード数
steps = self.get_parameter('steps').value
# dqnEnv.Envのインスタンスを生成する
# rclpy.init()
env = Env(state_size, action_size)
# DQNのネットワーク定義
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(action_size))
model.add(Activation('linear'))
print(model.summary())
# モデルのコンパイル
# experience replay用のmemory
memory = SequentialMemory(limit=50000, window_length=1)
# 行動方策はオーソドックスなepsilon-greedy
# 他に、各行動のQ値によって確率を決定するBoltzmannQPolicyが利用可能
policy = EpsGreedyQPolicy(eps=0.1)
# 初めての学習の場合はwarmupする
if mode == 'first':
dqn = DQNAgent(
model=model, nb_actions=action_size, memory=memory,
nb_steps_warmup=10, target_model_update=1e-2,
policy=policy)
else:
dqn = DQNAgent(
model=model, nb_actions=action_size, memory=memory,
target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
# 継続学習の訓練と、テストの場合は学習済みの重みをロード
weightPath = '/home/kenichi/ros2_ws/src/mtb3_sim/weights/weights.h5f'
if mode != 'first':
dqn.load_weights(weightPath)
# 訓練であればdqn.fit()、テストであればdqn.test()を実行
if mode != 'test':
dqn.fit(
env, nb_steps=steps, visualize=False,
verbose=2, nb_max_episode_steps=dsEpisMax)
dqn.save_weights(weightPath, overwrite=True)
else:
dqn.test(env, nb_episodes=steps, visualize=False)
# 最後のプロットを保存
savePath = '/home/kenichi/ros2_ws/src/mtb3_sim'
os.makedirs(os.path.join(savePath, 'plots'), exist_ok=True)
env.reset()
env.plt.savefig(os.path.join(savePath, 'plots/plot.png'))
def main():
rclpy.init()
dd = DqnDriveNode()
if __name__ == '__main__':
main()
一方、ROS1からROS2になったことによる建付けの変更があります。これも上述の「5.2 ドライブノード」に説明がありますが、ROS1のrospyの代りにROS2のrclpyを使う際にはそのプログラムをクラス化して、Nodeクラスを継承する必要があります。ローンチファイルのパラメータを取得するのにもrospyないしはrclpyが必要なので、ROS2のmtb3_dqn_5.pyではプログラム主要部をクラス化してNodeクラスを継承する形になっています。mtb3_dqn_5.pyはdqnEnv_5.pyのインスタンスを生成し、dqnEnv_5.pyがtb3_0に目標姿勢を送信するrobot_navigator.pyのインスタンスを生成しますが、dqnEnv_5.pyについては次項以降に説明して行きます。
#!/usr/bin/env python
import time
import numpy as np
import math
from math import pi
import matplotlib.pyplot as plt
import gym
import gym.spaces
import rclpy
from rclpy.node import Node
from tf_transformations import euler_from_quaternion
from geometry_msgs.msg import Pose, PoseStamped
from nav_msgs.msg import Odometry
from sensor_msgs.msg import LaserScan
from nav2_simple_commander.robot_navigator import BasicNavigator
class Env(gym.core.Env):
def __init__(self, state_size, action_size):
self.stepCnt = 0
self.totalSteps = 0
self.stepRewSum = 0.
self.totalGoals = 0
self.firstEpis = True
self.fwd_flg = True
self.goal_pos = PoseStamped()
self.goal_x = 0
self.goal_y = 0
self.position = Pose().position
self.yaw = 0.
self.heading = 0
self.plt_act_x = 0 # self.plt_act_xsにappendする要素をカウントアップ
self.plt_act_xs = [] # self.actionsを散布図にする時の横軸
self.actions = []
self.plt_rew_xs = [] # self.rewardsを散布図にする時の横軸
self.rewards = []
self.plt_goal_xs = [] # self.goalDursを散布図にする時の横軸
self.goalDurs = []
self.plot_flg = False
# tb3_0のナビゲーションを行うBasicNavigatorクラスのインスタンスを生成
self.navi = BasicNavigator()
# Set the first pose
self.pose_1 = PoseStamped()
self.pose_1.header.frame_id = 'map'
self.pose_1.header.stamp = self.navi.get_clock().now().to_msg()
self.pose_1.pose.position.x = -2.0
self.pose_1.pose.position.y = -0.8
self.pose_1.pose.orientation.z = 0.0
self.pose_1.pose.orientation.w = 1.0
# Set the second pose
self.pose_2 = PoseStamped()
self.pose_2.header.frame_id = 'map'
self.pose_2.header.stamp = self.navi.get_clock().now().to_msg()
self.pose_2.pose.position.x = 1.7
self.pose_2.pose.position.y = -1.0
self.pose_2.pose.orientation.z = -0.707107
self.pose_2.pose.orientation.w = 0.707107
# Set the first pose as an initial pose
self.navi.setInitialPose(self.pose_1)
# Wait for navigation to fully activate, since autostarting nav2
self.navi.waitUntilNav2Active()
self.epis_start = self.navi.get_clock().now()
# tb3_0のオドメトリ位置を取得するためのサブスクライバを生成する
self.sub_odom = self.navi.create_subscription(
Odometry, 'odom', self.getOdometry, 10)
# tb3_0のscan_rangeを取得するためのサブスクライバを生成する
self.scan_data3 = LaserScan()
self.scan_range = []
self.scan3 = self.navi.create_subscription(
LaserScan, 'scan3', self.getScan3, 10)
self.scan4 = self.navi.create_subscription(
LaserScan, 'scan4', self.getScan4, 10)
# 行動空間を設定
self.action_space = gym.spaces.Discrete(action_size)
# 観測空間を設定: 64行目のforループによる変換で最小値は0、最大値は3.5
# Pythonでは要素数が1つのタプルは(R,)と表記するので1次元配列のshapeは(R,)となる
self.observation_space = gym.spaces.Box(
low=0., high=3.5, shape=(state_size,))
def getOdometry(self, odom):
self.position = odom.pose.pose.position
orientation = odom.pose.pose.orientation
orientation_list = [orientation.x, orientation.y,
orientation.z, orientation.w]
_, _, self.yaw = euler_from_quaternion(orientation_list)
goal_angle = math.atan2(self.goal_y - self.position.y,
self.goal_x - self.position.x)
# headingはゴールの方位と自身のyaw角の差分(-π~πのラジアン)
heading = goal_angle - self.yaw
if heading > pi:
heading -= 2 * pi
elif heading < -pi:
heading += 2 * pi
self.heading = round(heading, 2)
def getScan3(self, scan_data3):
# getScan4()でも使用するためにインスタンス変数にする
self.scan_data3 = scan_data3
def getScan4(self, scan_data4):
# 以下のデータからなるscan_bothを生成する
scan_both = self.scan_data3.ranges[4:185:15] \
+ scan_data4.ranges[19:170:15]
# 無限大と非数を置換してself.scan_rangeを取得する
scan_range = []
for i in range(360 // 15):
# infはで無限大(float型が取得る最大値を超える数)を表すfloat型オブジェクト
if scan_both[i] == float('Inf'):
scan_range.append(3.5)
# nanは非数(欠損値)を表すfloat型オブジェクトでfloat('nan')で生成されるが、
# 非数同士を==で比較してもFalseとなるため非数かどうかはnp.isnan()で判定
elif np.isnan(scan_both[i]):
scan_range.append(0)
else:
scan_range.append(scan_both[i])
self.scan_range = scan_range
def getState(self):
while self.scan_range == []:
rclpy.spin_once(self.navi)
scan_range = self.scan_range
heading = self.heading
current_distance = round(math.hypot(
self.goal_x - self.position.x, self.goal_y - self.position.y), 2)
obstacle_min_range = round(min(scan_range), 2)
obstacle_angle = np.argmin(scan_range)
'''
state = scan_range + [heading, current_distance,
obstacle_min_range, obstacle_angle]
'''
state = [heading, current_distance,
obstacle_min_range, obstacle_angle]
return state
def setReward(self, done):
if done:
self.totalGoals += 1
self.navi.get_logger().info(
"Goal!! %d times" % self.totalGoals)
move_dist = math.hypot(
self.step_pos.x - self.position.x,
self.step_pos.y - self.position.y)
stepDur = self.navi.get_clock().now() - self.step_time
'''
if move_dist < 0.01:
reward = -50.
else:
reward = stepDur.nanoseconds * 1.e-9
'''
if move_dist < 0.01:
reward = -1.
else:
reward = 1.
self.step_pos = self.position
self.step_time = self.navi.get_clock().now()
return reward
def plot_durs(self, totalGoals, goalDurs):
plt.close("all")
plt.rcParams['font.size'] = 14
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.rcParams['toolbar'] = 'None'
fig, ax = plt.subplots()
mngr = plt.get_current_fig_manager()
mngr.window.setGeometry(0, 0, 800, 480)
totalTime = sum(goalDurs)
meanDur = round(totalTime / totalGoals, 1) \
if totalGoals != 0 else 0
ax.set_title(f"Goals: {totalGoals} " +
f"Mean Duration: {meanDur} s")
ax.set_xlabel('Number of DQN Steps', fontsize=16)
ax.set_ylabel('Duration (sec)', fontsize=16)
ax.set_position([0.14, 0.15, 0.8, 0.75])
ax.plot(self.plt_goal_xs, goalDurs)
ax.scatter(self.plt_act_xs, self.actions, marker='+', color='red')
ax.scatter(self.plt_rew_xs, self.rewards, marker='*', color='blue')
ax.set_xlim(left=0)
ax.set_ylim(bottom=0.)
plt.pause(0.1)
return plt
def step(self, action):
done = False
# self.firstStepがFalseの場合はactionに応じた回復行動を取る
if not self.firstStep:
# self.actionsの横軸の値と縦軸の値を同時にappendする
self.plt_act_xs.append(self.plt_act_x)
self.actions.append((action + 1) * 10.)
acts = str(action) * 3
self.navi.get_logger().info("action: %s %s" % (acts, type(action)))
# 回復行動が成功するか、3回失敗するまで繰返す
for i in range(3):
self.navi.clearAllCostmaps()
if action == 0:
self.navi.backup(0.2, 0.1)
elif action == 1:
self.navi.spin(0.78)
else:
self.navi.spin(-0.78)
out_break = False
while True:
time.sleep(1.)
if self.navi.isTaskComplete():
out_break = True
break
elif self.navi.status == 6:
break
if out_break:
break
self.navi.goToPose(self.goal_pos)
# 6秒以上停止するか、ゴールするまでstepを継続する
spinCnt = 0
stopCnt = 0
while True:
time.sleep(0.1)
move_dist = math.hypot(
self.spin_pos.x - self.position.x,
self.spin_pos.y - self.position.y)
goal_dist = math.hypot(
self.goal_x - self.position.x,
self.goal_y - self.position.y)
if move_dist < 0.01 and goal_dist > 0.1:
stopCnt += 1
if stopCnt > 60:
break
else:
self.spin_pos = self.position
stopCnt = 0
spinCnt += 1
if spinCnt % 10 == 0:
if self.navi.isTaskComplete():
done = True
self.plot_flg = True
break
if self.navi.status == 6:
self.navi.goToPose(self.goal_pos)
# "matplotlibの応答がありません"という警告を回避するため5秒毎にグラフを更新
if spinCnt % 50 == 0:
self.plot_durs(self.totalGoals, self.goalDurs)
# この後回復行動に入るのでself.navi.goToPose(self.goal_pos)を一旦終了する
self.navi.cancelTask()
state = self.getState()
reward = self.setReward(done)
# self.firstStepがTrueの場合はrewardを0にする
if self.firstStep:
reward = 0.
self.firstStep = False
# self.rewardsの横軸の値と縦軸の値を同時にappendする(横軸はactionと同じ)
else:
self.plt_rew_xs.append(self.plt_act_x)
self.rewards.append((reward + 9) * 5.)
self.plt_act_x += 1
# ステップ毎のrewardを今までの合計に加算し、ステップカウンタをカウントアップ
self.stepRewSum += reward
self.stepCnt += 1
self.totalSteps += 1
# ステップ数、アクション、報酬を出力
self.navi.get_logger().info(
"step: %3d, sum: %4d, Rew: %7.2f, Sum: %7.2f"
% (self.stepCnt, self.totalSteps, reward, self.stepRewSum))
# 次のstate、reward、done、追加情報(特にないので空dict)を順番に返す
return np.asarray(state), reward, done, {}
def reset(self):
self.firstStep = True
self.spin_pos = self.position
self.step_pos = self.position
self.step_time = self.navi.get_clock().now()
if self.firstEpis:
self.firstEpis = False
else:
self.stepCnt = 0
# ゴールに要したfloat型の秒数をリストgoalDursに追記
# self.goalDursの横軸の値と縦軸の値を同時にappendする
self.plt_goal_xs.append(self.plt_act_x)
goalDur = self.navi.get_clock().now() - self.epis_start
self.goalDurs.append(goalDur.nanoseconds * 1.e-9)
# ゴール直後にもグラフをプロットして最終保存用にself.pltとする
# 学習終了後に余分なプロットをしないようにself.plot_flgで判断
if self.plot_flg:
self.plt = self.plot_durs(self.totalGoals, self.goalDurs)
self.plot_flg = False
self.epis_start = self.navi.get_clock().now()
self.fwd_flg = not self.fwd_flg
# Publish the second or first pose as goal
self.goal_pos = self.pose_2 if self.fwd_flg else self.pose_1
self.goal_x = self.goal_pos.pose.position.x
self.goal_y = self.goal_pos.pose.position.y
# self.navi.goToPose(self.goal_pos)
state = self.getState()
return np.asarray(state)
5.2 ステップとaction
DRLでAMRの進路を決定するdqn_drive3では、LiDARのスキャン周期である1Hzでステップを刻み、この周期でactionを決定して速度に反映させていました。一方、dqn_navi5ではactionによってどの回復行動を取るかを决めるので、回復行動を取る局面になるまで同じステップが継続します。dqn_drive3と比較するとステップの継続時間は長く、その長さも毎回変ることになります。回復行動を取る局面とはRoundRobinを実行するタイミング、つまりnavigate_..._recovery.xmlに従ってround_robin_node.cppがコールされた時です。dqnEnv_5.pyに至る前に作成したバージョンdqnEnv_3.pyではこれに合せてステップを刻むことを考えました。
round_robin_nodeノードをクライアント、dqnEnv_3ノードをサーバとするサービス通信を行い、round_robin_nodeからのメッセージ受信でdqnEnv_3はステップを終了し、actionをメッセージとして返すことにしたのです。多大な労力は要しましたが、このサービス通信はちゃんと動作するようになりました。しかし、ステップの最初で決定したactionがround_robin_nodeにメッセージとして返されるのはそのステップの終了時であり、その回復行動が実行されるのは次のステップの終了時になるという問題が残りました。actionに応じた動作をしてrewardを得るという流れが1つのステップ内で完結しないのです。
この問題によるものかどうかは分りませんが、結論としてdqnEnv_3.pyを使うdqn_navi3は全く学習しませんでした。そこでまた考え抜いた上に思いついたのが、そもそもRoundRobinを使う必要はないのではないかということです。回復行動が必要なのは経路が設定できなかった時ですが、別の見方をすればtb3_0が動けなくなった時です。そこで、tb3_0が6秒間移動しない場合にステップを終了し、次のステップでactionに基づく回復行動を取ることにしました。この回復行動にはRoundRobinを使わず、back_up.cppもしくはspin.cppを直接コールします。RoundRobinの方はnavigate_..._recovery.xmlで0.1秒の待機にして無意味化します。
6秒間移動しないというステップ区切りはdqnEnv_5.pyの213~238行目で規定されています。216行目からのwhileループでは217行目によって0.1秒刻みで判断を繰返します。whileループ前半の218~230行目では、0.1秒間に動いた距離move_distとゴールまでの距離goal_distを算出し、move_dist < 0.01(速度0.1m/s未満)かつgoal_dist > 0.1だと動けなくなっていると判断します。2番目の条件は、ゴール近傍では向きの調整でその場旋回している場合があるのでこれを除外します。この状態が60回(6秒)続くとbreakでループを抜けます。
ループ後半の231~236行目では、1秒間隔でタスクが完了した(ゴールした)かどうかを確認し、完了すればbreakでループを抜けるとともに、done = Trueでエピソード終了のフラッグを立てます。237行目のself.navi.status == 6はタスクが失敗したと判断された場合で、タスクに時間がかかりすぎた場合に発生します。この場合はループは抜けず、238行目で再度同じタスクを指令します。whileループを抜けるとステップの終了処理をして、次のステップが開始されるとactionによる回復行動を取ることになります。
回復行動を取るのはdqnEnv_5.pyの193~211行目です。そもそも6秒間移動できなかった場合に回復行動を取るので、self.navi.wait()をしても意味がありません。そこでactionによって選択する回復行動はbackup(0.2, 0.1)、spin(0.78)、spin(-0.78)の3つにしています。それぞれ、秒速0.1mで0.2mだけ後退、45°左旋回、45°右旋回です。ここではその回復行動がタスクなので、203~209行目のwhileループでタスクが完了すれば外側のforループも抜けます。タスクが失敗の場合はwhileループだけを終了してforループで3回まで同じ回復行動を繰返します。このタスク失敗とは何なのかについては次項の第4段落以降に説明します。
5.3 stateとreward
dqnEnv_5.pyの119~134行目にあるgetState()関数は、当初はmtb3_dqn_18のgetState()と同じで、コメントアウトした129~130行目のようにしていました。しかし、学習が進むと回復行動として後退しか選択しなくなります。そこで、132~133行目のように24方位のスキャンデータをstateの要素から除外しました。24方位データの特徴量として抽出されたobstacle_min_rangeとobstacle_angleがstateに入っているのに、生データであるスキャンデータを同列に並べると、DQNへの入力が多すぎて因果関係が把握できないのではないかと考えたのです。残念ながら、この変更だけでは後退しか選択しなくなる症状は改善されませんでした。
一方、rewardについてはmtb3_dqn_18と全く違う考え方になっています。dqn_navi5のactionは回復行動を選択することなので、その選択が正しかったかどうかはゴールしたかやゴールまでに時間がかかったということで判断されるものではないと考えました。ましてや、yaw_reward[]とdistance_rateから意味不明の計算式で算出されるrewardとはさらさら関係ありません。そこでまず考えたのが、dqnEnv_5.pyの146~149行目にある今はコメントアウトされているrewardです。回復行動を取ったのに動けないままであれば-50、動けた場合はその後に継続して動けた時間(そのステップが終了するまでの秒数)をrewardとしました。
stateの変更だけでは学習に改善が認められなかったので、さらにrewardの変更を検討しました。色々とググった結果、「深層強化学習と活用するためのコツ」の27頁にあるReward clippingに行き着きました。それに倣ったのが151~154行目にあるrewardで、回復行動を取ったステップの終了時点でtb3_0が0.01m以上移動していれば+1、移動できなければ-1としました。この変更によって、偶発性に左右されるもののうまく学習する場合もあるという状況に持込めました。キャプチャ動画のところで書いた「青*はその回復行動が有効であったかどうかを示す」というのは、このrewardが+1か-1かということです。
以上の修正を経て、最後に残った課題がactionで後退を選択しているのに実際には動けないという状況が発生することです。この場合、タスク失敗が3回続いてステップが終了して、次のステップでまた後退を選択して動けないということが延々と続きます。後退を選択しているのに動けないのは、衝突モニタのせいです。tb3_0が前進で静止障害物に接近して停止エリア内に障害物が入ってしまうと、本来であれば後退して回復すればいいはずなのに衝突モニタが後退を含めた移動自体を禁止してしまうのです。
そんな馬鹿な話はないということで導入されたのがVelocityPolygonで、速度範囲によって衝突回避ポリゴンを変更できます。しかし、VelocityPolygonの導入はROS2のバージョンIron IrwiniからでHumbleでは使えません。 困ったなあと思いながらcollision_monitor_node.cppを眺めていると、停止エリアと減速エリアに入った時に速度をどう変更するかは406~426行目で規定されていることが分りました。ここを変更すれば、VelocityPolygonと実質的に同じことができます。まず、collision_monitor_params.yamlでPolygonStopより若干大きめのPolygonSlowを設定するのではなく、PolygonStopは前方、PolygonSlowは後方のエリアに設定します。
その上で、collision_monitor_node.cppの406~426行目でPolygonStopでは並進速度が正の場合のみ0にすると規定し、PolygonSlowでは並進速度が負の場合のみ0にすると規定するのです。そうすれば、前方に障害物があるために後退できないという状況は回避できるはずです。ただ、これで万事解決という訳には行かず、actionで後退を選択しても動けないという事態がやはり発生します。最終的には現在のプログラムの421行目にあるように後方に障害物がある場合は速度を0.1倍にして微速後退することにしました。以上の変更を行った後にdqn_navi5を実行したのが、冒頭のキャプチャ動画になります。
ROSとAnyLogicにDRLを取込むという目標は曲りなりにも達成できたと思います。本章の冒頭に書いた通り、今の「これぞAI」は生成AIになりましたが、だからと言ってDRLの価値が下がるというものではないでしょう。妙な言い方になりますが、生成AIはソフト応用のためのソフトなのに対し、DRLはハード(ロボット、自動運転)に展開できるソフトだと思います。まだまだ先の話になると思いますが、生成AIは「AIが新たなAIを生出す」シンギュラリティに繋がるでしょう。一方、「コンピュータには身体がないから実生活を体験できず、人間の知能を凌ぐことはできない」という説に対抗する端緒がDRLなのではないでしょうか。
話は変りますが、VII章の最後には
この趣味の成果を広く世の中に知らしめたいという思いは、どうやって知らしめたらいいかという難問に阻まれていました。そこで、「駄待ち狐こと松田賢一が作成した色々なプログラムを紹介します」というサイトを立上げ、そのトリとしてROSを取上げることにしたのです。
と書きました。一方、VIII章の最後には
「駄待ち狐のサイト」はプログラミングに仮託した自分史です。「凡人の自分史ほどつまらないものはない」という考えとの折合いを付けるため、そしてプログラミングのキーワードで検索してくれる人がいるかもしれないというささやかな希望に基いて、自分が作成した色々なプログラムを紹介しているのです。
と書いています。「どっちが本当なの??」と言われそうですが、どちらも本当です。駄待ち狐のサイトは趣味でいじったROSプログラムを紹介したいという思いと、自分史を残したいという願いの両方を叶える手段として立上げました。
残念ながら、今のところこれらの目的は全く達成できていません。Google Search Consoleによれば、過去6ヶ月間にグーグル検索で本サイトが表示された回数は217回で、クリックされた回数は22回だそうです。タイトル画像に記載しているfoxのアドレス宛てのメールは一通も届いていません。本サイトに関連したことでなくても、プログラミング全般に関する質問や四方山話など何でも結構ですので、fox宛てにお送りいただければ有難い限りです。いつの日か、「お便りありがとう」というX章を書き起こせる日が来ることを夢見ながら、一旦はここでノートPCを閉じたいと思います。